[연재기획]피지컬 AI, 산업의 미래를 다시 그리다⑥, “멀티모달 AI 피지컬 AI 시대 ‘두뇌’이자 ‘언어’”
기사입력 2025.12.09 11:14
“멀티모달 AI 피지컬 AI 시대 ‘두뇌’이자 ‘언어’”
로봇 언어·시각·행동 동시 이해 실행 범용 지능 핵심 기술
구글·엔비디아·피규어 AI 등 글로벌 기업들 기술 경쟁 치열
구글·엔비디아·피규어 AI 등 글로벌 기업들 기술 경쟁 치열
[편집자주]기존의 AI가 디지털 데이터 속에서 추론과 생성에 집중했다면 피지컬 AI(Physical AI)는 센서, 엣지 컴퓨팅, 로봇, 제어 시스템 등을 통해 현실 세계에서 직접 행동하고 반응한다. 피지컬 AI의 구현은 현실 세계에서 AI가 직접 행동하고 문제를 해결하기 때문에 산업 혁신과 자동화를 크게 진화 시킬 수 있으며, 현실 세계와 직접 상호작용한다. 이에 따라 엔비디아, 테슬라, 구글을 비롯해 글로벌 기업들은 피지컬 AI에 막대한 투자를 진행 중이며, 관련 시장도 폭발적으로 증가할 전망이다. 이러한 피지컬 AI를 구현하기 위해서는 센서 등 인식 기술을 비롯해서 실시간 데이터 처리를 위한 로컬 연산 등 엣지 컴퓨팅 및 임베디드 시스템, 로보틱스 및 제어기술이 필수다. 이에 e4ds news는 연재 기획을 통해 피지컬 AI의 개념에서부터 시장 전망, 관련 기술, 실제 사례 등 핵심 기술과 구현 전략을 살펴보는 자리를 마련했다.

▲사진 : pixabay.com
인공지능(AI)이 단순히 데이터를 분석하고 언어를 처리하는 단계를 넘어, 물리적 세계와 직접 상호작용하는 피지컬 AI(Physical AI) 시대로 진입하고 있다.
로봇이 센서를 통해 세상을 인지하고, 액추에이터로 움직이며, 실제 환경에서 자율적으로 과업을 수행하는 이 흐름은 ‘생각하는 AI’에서 ‘행동하는 AI’로의 전환을 상징한다.
이 과정에서 가장 핵심적인 기술로 부상한 것이 바로 멀티모달 AI(Multi-modal AI)다.
멀티모달 AI란 텍스트, 이미지, 영상, 행동 데이터 등 서로 다른 형태의 정보를 동시에 학습하고 이해하는 인공지능을 말한다.
기존의 언어 모델이 텍스트만을 처리했다면, 멀티모달 AI는 시각·언어·행동을 통합적으로 인식해 로봇이 보다 인간적인 방식으로 명령을 이해하고 수행할 수 있게 한다.
예컨대 “사과를 집어줘”라는 단순 지시뿐 아니라 “배고픈데 건강한 간식을 찾아줘”와 같은 추상적이고 의미론적인 명령도 처리할 수 있다.
이는 로봇이 단순 반복 작업을 넘어, 예측 불가능한 상황에 대응할 수 있는 일반화된 지능을 갖추게 하는 핵심 열쇠다.
피지컬 AI 구현에서 멀티모달 AI가 중요한 이유는 명확하다.
로봇은 현실 세계에서 다양한 감각 데이터를 동시에 받아들인다.
카메라가 제공하는 시각 정보, LiDAR가 생성하는 공간 데이터, 촉각 센서가 감지하는 압력과 질감, 그리고 사용자가 전달하는 언어적 지시가 모두 결합돼야 한다.
멀티모달 AI는 이러한 이질적인 데이터를 하나의 통합된 지능으로 연결해, 로봇이 실제 환경에서 자연스럽게 행동할 수 있도록 한다.
결국 멀티모달 AI는 피지컬 AI의 ‘두뇌’ 역할을 담당하는 셈이다.
글로벌 기업들은 이미 멀티모달 AI를 중심으로 치열한 경쟁을 벌이고 있다.
구글 딥마인드는 ‘RT-2(Robotic Transformer 2)’를 통해 웹 스케일 데이터와 로보틱스 데이터를 결합한 비전-언어-행동(VLA) 모델을 선보였다.
RT-2는 기존 훈련 데이터에 없던 새로운 물체를 인식하고 추상적 명령을 해석하는 등 ‘창발적 능력’을 보여주며, 로봇 지능의 새로운 가능성을 열었다.
엔비디아(NVIDIA)는 하드웨어와 시뮬레이션 생태계를 기반으로 ‘GR00T’라는 범용 휴머노이드 파운데이션 모델을 개발 중이다.
GR00T는 엔비디아의 시뮬레이션 플랫폼 Isaac Sim에서 생성된 방대한 합성 데이터를 학습하며, 텍스트·이미지 프롬프트를 통해 다양한 행동을 습득한다.
이는 멀티모달 AI가 단순히 소프트웨어에 머무르지 않고, 하드웨어·시뮬레이션·데이터 파이프라인을 아우르는 플랫폼 경쟁의 중심에 있음을 보여준다.
스타트업 피규어 AI(Figure AI) 역시 멀티모달 AI를 활용해 범용 휴머노이드 로봇을 개발하고 있다.
이들은 한때 OpenAI와 협력해 비전-언어 모델(VLM)을 로봇 두뇌로 탑재, 인간과 자연어로 대화하며 주변 상황을 인식하고 행동하는 로봇을 선보였다.
비록 협력은 단기간에 종료됐지만, ‘최고의 AI 두뇌 + 민첩한 하드웨어’라는 조합이 피지컬 AI의 미래를 상징적으로 보여준 사례로 평가된다.
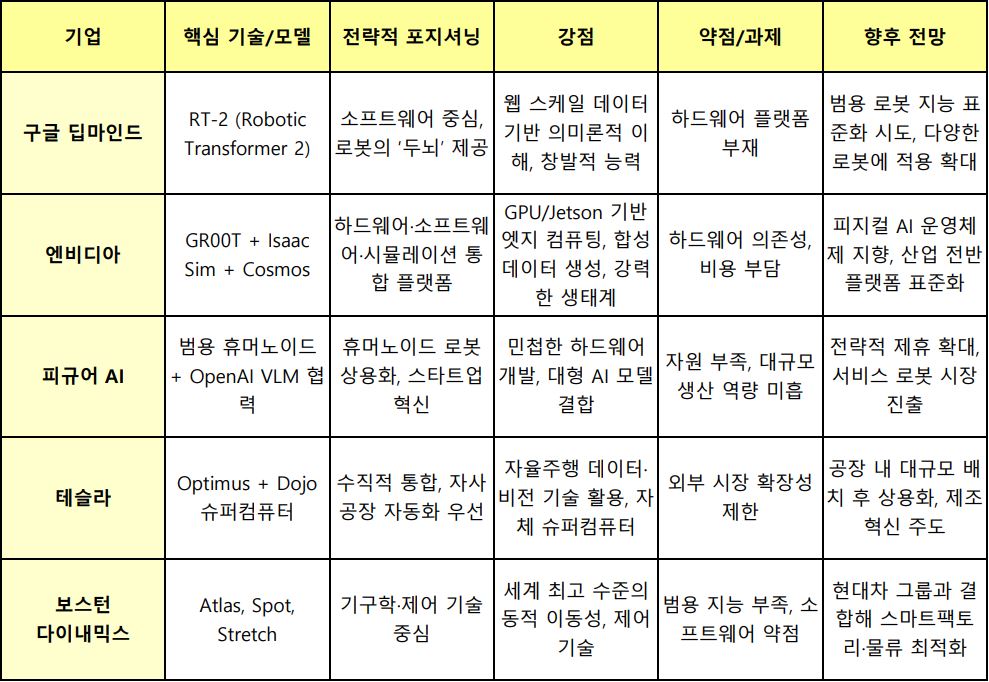
▲기업별 모티모달 AI 전략 비교
향후 멀티모달 AI의 발전은 피지컬 AI 상용화의 성패를 좌우할 전망이다.
첫째, 시뮬레이션을 통한 합성 데이터 생성이 더욱 중요해질 것이다.
현실 세계에서 방대한 행동 데이터를 수집하는 것은 비용과 안전 문제로 제약이 크다.
따라서 고충실도의 디지털 트윈 환경에서 멀티모달 데이터를 대량으로 생산하고 학습하는 방식이 주류가 될 가능성이 높다.
둘째, 크로스 임바디먼트(Cross-embodiment) 기술이 발전하면서 하나의 멀티모달 AI 모델을 다양한 로봇 플랫폼에 적용할 수 있게 될 것이다.
이는 로봇 산업의 범용성을 크게 높여, 스마트 팩토리부터 가정용 서비스 로봇까지 광범위한 응용을 가능하게 한다.
셋째, 통신 인프라의 진화도 멀티모달 AI의 확산을 가속할 것이다.
5G와 6G 네트워크는 로봇과 클라우드 두뇌 간의 초저지연 연결을 지원해, 멀티모달 AI가 실시간으로 작동할 수 있는 기반을 제공한다.
결국 멀티모달 AI는 피지컬 AI 시대의 ‘두뇌’이자 ‘언어’다.
로봇이 인간과 같은 방식으로 세상을 보고, 듣고, 이해하며 행동하기 위해서는 멀티모달 AI가 필수적이다.
글로벌 기업들의 전략은 단순히 기술 경쟁을 넘어, 하드웨어·소프트웨어·데이터·통신을 통합하는 플랫폼 경쟁으로 확장되고 있다.
피지컬 AI의 미래는 멀티모달 AI가 얼마나 빠르게, 그리고 얼마나 정교하게 현실 세계와 융합할 수 있는지에 달려 있다.

관련뉴스
-

[연재기획]피지컬 AI, 산업의 미래를 다시 그리다①, “‘피지컬 AI 성공’ 인간과 지능형 기계의 상호작용 설계에 달렸다”
기존의 AI가 디지털 데이터 속에서 추론과 생성에 집중했다면 피지컬 AI(Physical AI)는 센서, 엣지 컴퓨팅, 로봇, 제어 시스템 등을 통해 현실 세계에서 직접 행동하고 반응한다. 피지컬 AI의 구현은 현실 세계에서 AI가 직접 행동하고 문제를 해결하기 때문에 산업 혁신과 자동화를 크게 진화 시킬 수 있으며, 현실 세계와 직접 상호작용한다. 이에 따라 엔비디아, 테슬라, 구글을 비롯해 글로벌 기업들은 피지컬 AI에 막대한 투자를 진행 중이며, 관련 시장도 폭발적으로 증가할 전망이다. 이러한 피지컬 AI를 구현하기 위해서는 센서 등 인식 기술을 비롯해서 실시간 데이터 처리를 위한 로컬 연산 등 엣지 컴퓨팅 및 임베디드 시스템, 로보틱스 및 제어기술이 필수다. 이에 e4ds news는 연재 기획을 통해 피지컬 AI의 개념에서부터 시장 전망, 관련 기술, 실제 사례 등 핵심 기술과 구현 전략을 살펴보는 자리를 마련했다.
2025-10-20 오후 3:31:16by 배종인 기자
-
.jpg)
[연재기획]피지컬 AI, 산업의 미래를 다시 그리다②, “‘피지컬 AI 시장’ 2030년 1조 달러 생태계 연다”
일부 전문가들에 따르면 ‘피지컬 AI(Physical AI)’는 산업혁명을 넘어서는 인류 역사상 가장 큰 혁명이 될 것이라는 전망이다. 사회, 문화, 경제적으로 큰 영향력을 가지지만 전체를 우리가 예측할 수 없기 때문에 경제적 관점에서 글로벌 시장조사 기관들의 전망을 인용하면 피지컬 AI는 2030년 약 1조 달러의 시장을 이룰 정도로 산업 구조를 뒤흔들 핵심 동력으로 자리 잡을 것으로 보인다. 산업 분야별로 피지컬 AI 시장 규모를 살펴봤다.
2025-10-27 오후 4:43:25by 명세환 기자
-

[연재기획]피지컬 AI, 산업의 미래를 다시 그리다③, “피지컬 AI 감각 기관 ‘센서’ 피지컬 AI 경쟁력 좌우”
기존의 AI가 디지털 데이터 속에서 추론과 생성에 집중했다면 피지컬 AI(Physical AI)는 센서, 엣지 컴퓨팅, 로봇, 제어 시스템 등을 통해 현실 세계에서 직접 행동하고 반응한다. 피지컬 AI의 구현은 현실 세계에서 AI가 직접 행동하고 문제를 해결하기 때문에 산업 혁신과 자동화를 크게 진화 시킬 수 있으며, 현실 세계와 직접 상호작용한다. 이에 따라 엔비디아, 테슬라, 구글을 비롯해 글로벌 기업들은 피지컬 AI에 막대한 투자를 진행 중이며, 관련 시장도 폭발적으로 증가할 전망이다. 이러한 피지컬 AI를 구현하기 위해서는 센서 등 인식 기술을 비롯해서 실시간 데이터 처리를 위한 로컬 연산 등 엣지 컴퓨팅 및 임베디드 시스템, 로보틱스 및 제어기술이 필수다. 이에 e4ds news는 연재 기획을 통해 피지컬 AI의 개념에서부터 시장 전망, 관련 기술, 실제 사례 등 핵심 기술과 구현 전략을 살펴보는 자리를 마련했다. 이번 편은 피지컬 AI의 감각 기관인 센서에 대해 다룬다.
2025-11-11 오전 8:48:24by 명세환 기자
-

“피지컬 AI, 인간-로봇 협동 혁신적 변화시킨다”
세이프틱스(Safetics) 주최로 11일 포스코타워 역삼 3층 이벤트홀에서 개최된 ‘협동로봇 5대 브랜드와 함께하는 Next-Gen Human-Robot Collaboration - Physical AI, 로봇 한계를 넘어서는 Game-Changer’ 세미나에서 고려대학교 인공지능학과 서승호 교수는 ‘실행하는 AI, 협업하는 로봇-Physical AI의 현재와 산업적용’을 주제로 발표했다. 서승호 교수는 “피지컬 AI(Physical AI)가 인간과 로봇의 협동을 혁신적으로 변화시킬 것”이라며, “AI와 로봇 기술이 실생활과 어떻게 연결되는지, 그리고 그 과정에서 데이터 수집과 해석, 실제 로봇의 움직임까지 이어지는 일련의 사이클이 중요하다”고 설명했다.
2025-11-12 오후 12:06:41by 배종인 기자
-

“피지컬 AI 성공, ROI가 관건”
세이프틱스(Safetics) 주최로 개최된 ‘Physical AI, 로봇 한계를 넘어서는 Game-Changer’ 세미나에서 서형주 카본식스 CTO는 ‘세계 최초의 산업용 Physical AI Kit’을 발표하며, “제조업에서 AI가 자리를 잡으려면 ROI가 관건”이라고 밝혔다.
2025-11-17 오전 8:31:45by 배종인 기자
-
.jpg)
“피지컬 AI의 미래, 데이터 수집·활용 능력에 의해 결정”
세이프틱스(Safetics) 주최로 개최된 ‘Physical AI, 로봇 한계를 넘어서는 Game-Changer’ 세미나에서 마음AI 최홍섭 대표는 ‘제조 중심 피지컬 AI 도입 전략’에 대해 발표하며, 피지컬 AI 성공 열쇠로 데이터 수집을 제시했다.
2025-11-17 오전 8:55:00by 배종인 기자
-
.jpg)
[연재기획]피지컬 AI, 산업의 미래를 다시 그리다④, “피지컬 AI, 자동화 격차 해소 핵심 열쇠 급부상”
인공지능(AI)이 물리적 세계와 직접 상호작용하는 ‘피지컬 AI(Physical AI)’ 시대가 도래하면서 제조와 물류 산업이 가장 먼저 변화의 파고를 맞고 있는 가운데, 피지컬 AI가 대중소 기업간 자동화 격차를 해소 할 수 있는 핵심 열쇠로 급부상하고 있다.
2025-11-24 오후 3:45:44by 배종인 기자
-
.jpg)
노타, 로봇·드론 등 피지컬 AI 시장 본격 공략
AI 경량화 및 최적화 전문기업 노타(대표 채명수)가 텔레칩스의 고성능 AP(Application Processor) ‘돌핀5(Dolphin5)’에 안면인식 AI 모델을 최적화 적용하며, 로봇, 드론 등 피지컬 AI 시장 본격 공략에 나섰다.
2025-11-25 오후 3:29:11by 배종인 기자
-
.jpg)
ST, 피지컬 AI 상용화 가속
글로벌 반도체 기업 ST마이크로일렉트로닉스(STMicroelectronics, 이하 ST)가 업계 최대 규모의 마이크로컨트롤러용 AI 모델 라이브러리 STM32 AI Model Zoo 4.0을 공개했다. 이번 확장판은 140개 이상의 비전·오디오·센싱 기반 모델을 제공하며, 임베디드 AI 애플리케이션의 프로토타이핑과 개발을 대폭 가속화 할 것으로 기대된다.
2025-11-27 오후 2:40:54by 배종인 기자
-

[연재기획]피지컬 AI, 산업의 미래를 다시 그리다⑤, “‘통합운영체계’ 승부처”
피지컬 AI 확산의 핵심 열쇠로 꼽히는 통합운영체계(Integrated Operating System) 선점하기 위해 엔비디아를 필두로 우리나라를 비롯한 주요 국가들이 개발과 표준화에 적극 나서고 있다.
2025-12-01 오후 4:08:35by 명세환 기자

.png)
.png)
관련 웨비나





많이 본 뉴스
[열린보도원칙] 당 매체는 독자와 취재원 등 뉴스이용자의 권리 보장을 위해 반론이나 정정보도, 추후보도를 요청할 수 있는 창구를 열어두고 있음을 알려드립니다.
고충처리인 장은성 070-4699-5321 , news@e4ds.com